
NatTable + Eclipse Collections = Performance & Memory improvements ?
Some time ago I got reports from NatTable users about high memory consumption when using NatTable with huge data sets. Especially when using trees, the row hide/show feature and/or the row grouping feature. Typically I tended to say that this is because of the huge data set in memory, not because of the NatTable implementation. But as a good open source developer I take such reports seriously and verified the statement to be sure. So I updated one of the NatTable examples that combine all three features to show about 2 million entries. Then I modified some row heights, collapsed tree nodes and hid some rows. After checking the memory consumption I was surprised. The diagram below shows the result. The heap usage goes up to and beyond 1.5 GB on scrolling. In between I performed a GC and scrolled again, which causes the those peaks and valleys.
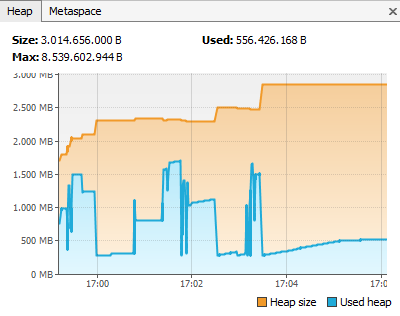
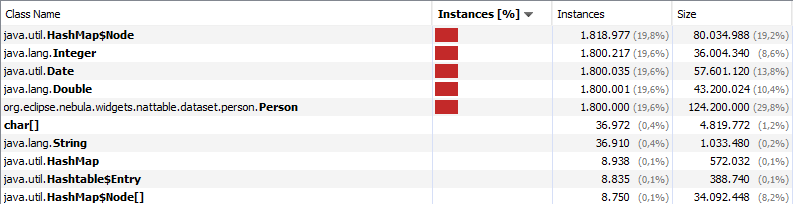
A more detailed inspection reveals that the high memory consumption is not because of the data in memory itself. There are a lot of primitive wrapper objects and internal objects in the map implementation that consume a big portion of the memory, as you can see in the following image.
Note:
Primitive wrapper objects have a higher memory consumption than primitive values itself. As there are already good articles about that topic available I will not repeat that. If you are interested in some more details in the topic Primitives vs Objects you can have a look at Baeldung for example.
So I started to check the NatTable implementation in search of the memory issue. And I found some causes. In several places there are internal caches for the index-position mapping to improve the rendering performance. Also the row heights and column widths are stored internally in a collection if a user resized them. Additionally some scaling operations incorrectly where using Double objects instead of primitive values to avoid rounding issues on scaling.
From my experience in an Android project I remembered an article that described a similar issue. In short: Java has no collections for primitive types, therefore primitive values need to be stored via wrapper objects. In Android they introduced the SparseArray to deal with this issue. So I was searching for primitive collections in Java and found Eclipse Collections. To be honest, I heard about Eclipse Collections before, but I always thought the standard Java Collections are already good enough, so why checking some third party collections. Small spoiler: I was wrong!
Looking at the website of Eclipse Collections, they state that they have a better performance and better memory consumption than the standard Java Collections. But a good developer and architect does not simply trust statements like “take my library and all your problems are solved”. So I started my evaluation of Eclipse Collections to see if the memory and performance issues in NatTable can be solved by using them. Additionally I was looking at the Primitive Type Streams introduced with Java 8 to see if some issues can even be leveraged using that API.
Creation of test data
Right at the beginning of my evaluation I noticed the first issue. Which way should be used to create a huge collection of test data to process? I read about some discussions using the good old for-loop vs. IntStream. So I started with some basic performance measurements to compare those two. The goal was to create test data with values from 0 to 1.000.000 where every 100.000 entry is missing.
The for-loop for creating an int[] with the described values looks like this:
int[] values = new int[999_991];
int index = 0;
for (int i = 0; i < 1_000_000; i++) {
if (i == 0 || i % 100_000 != 0) {
values[index] = i;
index++;
}
}
Using the IntStream API it looks like this:
int[] values = IntStream.range(0, 1_000_000)
.filter(i -> i == 0 || i % 100_000 != 0)
.toArray();
Additionally I wanted to compare the performance for creating an ArrayList<Integer> via for-loop and IntStream.
ArrayList<Integer> values = new ArrayList<>(999_991);
for (int i = 0; i < 1_000_000; i++) {
if (i == 0 || i % 100_000 != 0) {
values.add(i);
}
}
List<Integer> values = IntStream.range(0, 1_000_000)
.filter(i -> (i == 0 || i % 100_000 != 0))
.boxed()
.collect(Collectors.toList());
The result is interesting, although not suprising. Using the for-loop for creating an int[] is the clear winner.
The usage of the IntStream is not bad but definitely worse than the for-loop.
So for recurring tasks and huge ranges a refactoring from for-loop to IntStream is not a good idea.
The creation of collections with wrapper objects is of course even worse, as wrapper objects need to be created via boxing.
collecting int[] via for-loop 1 ms
collecting int[] via IntStream 4 ms
collecting List<Integer> via for-loop 7 ms
collecting List<Integer> via IntStream 13 ms
I also tested the usage of HashSet and TreeSet for the wrapper objects, as typically in NatTable I need distinct values, often sorted for further processing. HashSet as well as TreeSet have a worse performance in the creation scenario, but TreeSet is the clear looser here.
collecting HashSet<Integer> via for-loop 16 ms
collecting TreeSet<Integer> via for-loop 189 ms
collecting Set<Integer> via IntStream 26 ms
Note:
Running the tests in a single execution, the numbers are worse, which is caused by the VM ramp up and class loading. Executing it 10 times the average numbers are similar to the above but are still worse because the first execution is that much worse. The numbers shown above are the average out of 100 executions. And even increasing the number of executions to 1.000 the average values are quite the same and sometimes even get drastically better because of the VM optimizations for code that gets executed often. So the numbers presented here are the average out of 100 executions.
After evaluating the performance of standard Java API for creating test data, I looked at the Eclipse Collections - Primitive Collections. I compared MutableIntList with MutableIntSet and used the different factory methods for creating the test data:
- Iteration directly operate on an initial empty
MutableIntListMutableIntList values = IntLists.mutable.withInitialCapacity(999_991); for (int i = 0; i < 1_000_000; i++) { if (i == 0 || i % 100_000 != 0) { values.add(i); } }Note:
The methodwithInitialCapacity(int)is introduced with Eclipse Collections 10.3. In previous versions it is not possible to specify an initial capacity using the primitive type factories, you can only create an emtyMutableIntListorMutableIntSetusingemtpy(). Without specifying the initial capacity, the iteration approach takes 3ms for theMutableIntListand 32ms for theMutableIntSet. - Factory method
of(int...)/with(int...)MutableIntList values = IntLists.mutable.of(inputArray); - Factory method
ofAll(Iterable<Integer>)/withAll(Iterable<Integer>)MutableIntList values = IntLists.mutable.ofAll(inputCollection); - Factory method
ofAll(IntStream)/withAll(IntStream)MutableIntList values = IntLists.mutable.ofAll( IntStream .range(0, 1_000_000) .filter(i -> (i == 0 || i % 100_000 != 0)));
To create MutableIntSet use the IntSetsutility class:
MutableIntSet values = IntSets.mutable.xxx
Note:
For the factory methods of course the generation of the input also needs to be taken into account. So for creating data from scratch the time for creating the array or the collection needs to be added on top.
The result shows that at creation time the MutableIntList is much faster than the MutableIntSet. And the usage of the factory method with an int[] parameter is faster than using an Integer collection or IntStream or the direct operation on the MutableIntList. The reason for this is probably that using an int[] the MutableIntList instances are actually wrapper to the int[]. In this case you alse need to be careful, as modifications done via the primitive collection are directly reflected outside of the collection.
creating MutableIntList via iteration 1 ms
creating MutableIntList of int[] 0 ms
creating MutableIntList via Integer collection 4 ms
creating MutableIntList via IntStream 6 ms
creating MutableIntSet via iteration 21 ms
creating MutableIntSet of int[] 32 ms
creating MutableIntSet of Integer collection 39 ms
creating MutableIntSet via IntStream 38 ms
In several use cases the usage of a Set would be nicer to directly avoid duplicates in the collection. In NatTable a sorted order is also needed often, but there is no TreeSet equivalent in the primitive collections. But the MutableIntList comes with some nice API to deal with this. Via distinct() we get a new MutableIntList that only contains distinct values, via sortThis() the MutableIntList is directly sorted.
The following call returns a new MutableIntList with distinct values in a sorted order, similar to a TreeSet.
MutableIntList uniqueSorted = values.distinct().sortThis();
When changing this in the test, the time for creating a MutableIntList with distinct values in a sorted order increases to about 27 ms. Still less than creating a MutableIntSet. But as our input array is already sorted and only contains distinct values, this measurement is probably not really meaningful.
The key takeaways in this part are:
- The good old for-loop still has the best performance. It is also faster than
IntStream.range(). - The
MutableIntListhas a better performance at creation time compared toMutableIntSet. This is the same with default Java List and Set implementations. - The
MutableIntListhas some nice API for modifications compared to handling a primitive array, which makes it more comfortable to use.
Usage of primitive value collections
As already mentioned, Eclipse Collections come with nice and comfortable API similar to the Java Stream API. But here I don’t want to go in more detail on that API. Instead I want to see how Eclipse Collections perform when using the standard Java Collections API and compare it with the performance of the Java Collections. By doing this I want to ensure that by using Eclipse Collections the performance is getting better or at least is not becoming worse than by using the default Java collections.
contains()
The first use case is the check if a value is contained in a collection. This is done by the contains() method.
boolean found = valuesCollection.contains(search);
For the array we compare the old-school for-loop
boolean found = false;
for (int i : valuesArray) {
if (i == search) {
found = true;
break;
}
}
with the primitive streams approach
boolean found = Arrays.stream(valuesArray).anyMatch(x -> x == search);
Additionally I added a test for using Arrays.binarySearch(). But the result is not 100% comparable, as binarySearch() requires the array to be sorted in advance. Since our array already contains the test data in sorted order, this test works.
boolean found = Arrays.binarySearch(valuesArray, search) >= 0;
We use the collections/arrays that we created before and first check for the value 450.000 which exists in the middle of the collection. Below you find the execution times of the different approaches.
contains in List 1 ms
contains in Set 0 ms
contains in int[] stream 2 ms
contains in int[] iteration 1 ms
contains in int[] binary search 0 ms
contains in MutableIntList 0 ms
contains in MutableIntSet 0 ms
Then we execute the same setup and check for the value 2.000.000 which does not exist in the collection. This way the whole collection/array needs to be processed, while in the above case the search stops once the value is found.
contains in List 2 ms
contains in Set 0 ms
contains in int[] stream 2 ms
contains in int[] iteration 1 ms
contains in int[] binary search 0 ms
contains in MutableIntList 0 ms
contains in MutableIntSet 0 ms
What we can see here is that the Java Primitive Streams have the worst performance for the contains() case and the Eclipse Collections perform best. But actually there is not much difference in the performance.
indexOf()
For people with a good knowledge of the Java Collections API the specific measurement of indexOf() might look strange. This is because for example the ArrayList internally uses indexOf() in the contains() implementation. And we have tested that before. But the Eclipse Primitive Collections are not using indexOf() in contains(). They operate on the internal array. Also indexOf() is implemented differently without the use of the equals() method. So a dedicated verification is useful. Below are the results for testing an existing value and a not existing value.
Check indexOf() 450_000
indexOf in collection 0 ms
indexOf in int[] iteration 0 ms
indexOf in MutableIntList 0 ms
Check indexOf() 2_000_000
indexOf in collection 1 ms
indexOf in int[] iteration 0 ms
indexOf in MutableIntList 0 ms
The results are actually not surprising. Also in this case there is not much difference in the performance.
Note:
There is no indexOf() for Sets and of course we can also not get an index when using Java Primitive Streams. So this test only compares ArrayList, iteration on an int[] and the MutableIntList. I also skipped testing binarySearch() here, as the results would be equal to the contains() test with the same restrictions.
removeAll()
Removing multiple items from a List is a big performance issue. Before my investigation here I was not aware on how serious this issue is. What I already knew from past optimizations is, that removeAll() on an ArrayList is much worse than iterating manually over the items to remove and then remove every item solely.
For the test I am creating the base collection with 1.000.000 entries and a collection with the values from 200.000 to 299.999 that should be removed. First I execute the iteration to remove every item solely
for (Integer r : toRemoveList) {
valueCollection.remove(r);
}
then I execute the test with removeAll()
valueCollection.removeAll(toRemoveList);
The tests are executed on an ArrayList, a HashSet, a MutableIntList and a MutableIntSet.
Additionally I added a test that uses the Primitive Stream API to filter and create a new array from the result. As this is not a modification of the original collection, the result is not 100% comparable to the other executions. But anyhow maybe interesting to see (even with a dependency to binarySearch()).
int[] result = Arrays.stream(values)
.filter(v -> (Arrays.binarySearch(toRemove, v) < 0))
.toArray();
Note:
The code for removing items from an array is not very comfortable. Of course we could also use some library like Apache Commons with primitive type arrays. But this is about comparing plain Java Collections with Eclipse Collections. Therefore I decided to skip this.
Below are the execution results:
remove all by primitive stream 21 ms
remove all by iteration List 29045 ms
remove all List 64068 ms
remove all by iteration Set 1 ms
remove all Set 1 ms
remove all by iteration MutableIntList 13602 ms
remove all MutableIntList 21 ms
remove all by iteration MutableIntSet 2 ms
remove all MutableIntSet 2 ms
You can see that the iteration approach on an ArrayList is almost twice as fast as using removeAll(). But still the performance is very bad. The performance for removeAll() as well as the iteration approach on a Set and a MutableIntSet are very good. Interestingly the call to removeAll() on a MutableIntList is also acceptable, while the iteration approach seems to have a performance issue.
The key takeaways in this part are:
- The performance of the Eclipse Collections is at least as good as the standard Java Collections. In several cases even far better.
- Some performance workarounds that were introduced with standard Java Collections could avoid the performance improvements if they are simply adapted with Eclipse Collections and not also changed.
Memory consumption
From the above measurements and observations I can say that in most cases there is a performance improvement when using Eclipse Collections compared to the standard Java Collections. And even for use cases where no big improvement can be seen, there is a small improvement or at least no performance decrease. So I decided to integrate Eclipse Collections in NatTable and use the Primitive Collections in every place where primitive values where stored in Java Collections. Additionally I fixed all places where wrapper objects were created unnecessarily. Then I executed the example from the beginning again to measure the memory consumption. And I was really impressed!
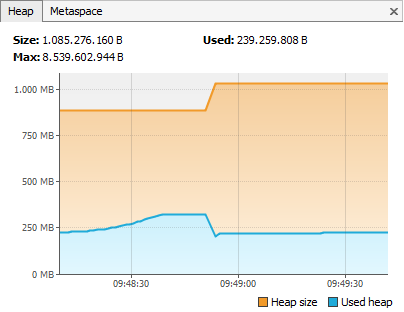
As you can see in the above graph, the heap usage stays below 250 MB even on scrolling. Remember, before using Eclipse Primitive Collections, the heap usage growed up to 1,5 GB. Going into more detail we can see that a lot of objects that were created for internal management are not created anymore. So now really the data model that should be visualized by NatTable is taking most of memory, not the NatTable itself anymore.
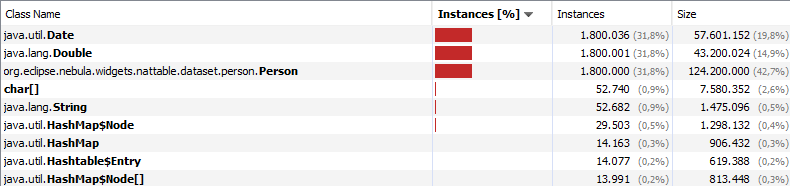
One thing I noticed in the tests is that there is still quite some memory allocated if the MutableIntList or MutableIntSet are cleared via clear(). Basically it is the same with the Java Collections. The collection allocates the space for the needed size. For the Eclipse Collections this means the internal array keeps its size as it only fills the array with 0. To even clean up this memory you need to assign a new empty collection instance.
Note:
The concrete IntArrayList class contains a trimToSize() method. But as you typically work agains the interfaces when using the factories, that method is not accessible, and also not all implementations contain such a method.
ArrayList vs. MutableList
The data to show in a NatTable is accessed by an IDataProvider. This is an abstraction to the underlying data structure, so that users can choose the data structure they like. The most common data structure in use is a List, and NatTable provides the ListDataProvider to simplify the usage of a List as underlying data structure. With the ListDataProvider as an abstraction there is no iteration internally. Instead there is a point access per cell via a nested for loop:
for (int column = 0; column < dataProvider.getColumnCount(); column++) {
for (int row = 0; row < dataProvider.getRowCount(); row++) {
dataProvider.getDataValue(column, row);
}
}
For the ListDataProvider this means, for every cell first the row object is retrieved from the List, then the property of the row object is accessed. As NatTable is a virtual table by design, it actually never happens that all values from the underlying data structure is accessed. Only the data that is currently visible is accessed at once. While an existing performance test in the NatTable performance test suite showed an impressive performance boost by switching from ArrayList to MutableList, a more detailed benchmark revealed that both List implementations have a similar performance. I can’t tell why the existing test showed such a big difference, probably some side effects in the test setup, as the numbers swap if the test execution is swapped.
Executing the benchmark with Java 8 and Java 11 on the other hand shows a difference. Using Java 11 as runtime the tests execute about 50% faster for both ArrayList and MutableList. And it also shows that with Java 11 it makes a difference if the nested iteration iterates column or row first. While with Java 8 the execution time was similar, with Java 11 the row first approach shows a better performance.
Conclusion
Being sceptic at the beginning and have to admit that Eclipse Collections are really interesting and useful when it comes to performance and memory usage optimizations with collections in Java. The API is really handy and similar to the Java Streams API, which makes the usage quite comfortable.
My takeaways after the verification:
- For short living collections it is often better to either use primitive type arrays, primitive streams or the
MutableIntList, which has the better performance at creation compared to theMutableIntSet. - For storing primitive values use
MutableIntSetorMutableIntList. This gives a similar memory consumption than using primitive type arrays, by granting a rich API for modifications at runtime. - Make use of the Eclipse Collections API to make implementation and processing as efficient as possible.
- When migrating from Java Collections API to Eclipse Collections, ensure that no workarounds are in the current code base. Otherwise you might loose big performance improvements.
- Even when using a library like Eclipse Collections you need to take care about your memory management to avoid leaks at runtime, e.g. create new instance in favour of clearing huge collections.
Based on the observations above I decided that Eclipse Collections will become a major dependency for NatTable Core. With NatTable 2.0 it will be part of the NatTable Core Feature. I am sure that internally even more optimizations are possible by using Eclipse Collections. And I will investigate where and how this can be done. So you can expect even more improvements in that area in the future.
In case you think my tests are incorrect or need to be improved, or you simply want to verify my statements, here are the links to the classes I used for my verification:
- CollectionsBenchmark
- PositionUtilBenchmark
- ListDataProviderBenchmark
- _817_TreeLayerWithRowGroupingExample
In the example class I increased the number of data rows to about 2.000.000 via this code:
List<Person> personsWithAddress = PersonService.getFixedPersons();
for (int i = 1; i < 100_000; i++) {
personsWithAddress.addAll(PersonService.getFixedPersons());
}
and I increased the row groups via these two lines of code:
rowGroupHeaderLayer.addGroup("Flanders", 0, 8 * 100_000);
rowGroupHeaderLayer.addGroup("Simpsons", 8 * 100_000, 10 * 100_000);
If some of my observations are wrong or the code can be made even better, please let me know! I am always willing to learn!
Thanks to the Eclipse Collections team for this library!
If you are interested in learning more about Eclipse Collections, you might want to check out the Eclipse Collections Kata.